SQL Pivot Tables
So i am a data analyst and my job in what i would like to call data mining exercises entails cross referencing large data sets that have little to no structured relationships. So i find myself writing huge complex select queries that at some point have to pivot the data around just to prepare it to be cross referenced with another complex query. Lucky for me its not much of a hustle when working with Oracle and Microsoft SQL server. The moment we start talking about MySQL, boy oh boy... that's a totally different story. There are workarounds to achieve this. One famous solution on the internet goes like this:
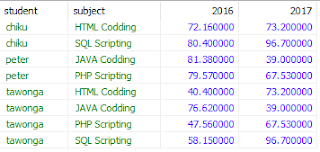
 Assuming we have a table that keeps track of student test scores like the one shown in the figure to the left. Lets also assume that we want to pivot this data by year. Thus our rows will have the student name and subject, our columns would be the respective year and the data cells would contain the average score.
Assuming we have a table that keeps track of student test scores like the one shown in the figure to the left. Lets also assume that we want to pivot this data by year. Thus our rows will have the student name and subject, our columns would be the respective year and the data cells would contain the average score.
The solution is to create computed columns in our select statement such that for any record that is for 2016 falls in the 2016 column and records for 2017 fall in 2017. Something like this:
select student, subject, if(yr=2016,score,null) `2016`, if(yr=2017,score,null) `2017` from test
Ok, at this point you are already beginning to see the problem here, 1- you need to know all values of yr in advance as these are hard coded into your select query and 2- to just change the column on which you pivot requires a change in your code... Anyways lets continue. Now you will notice that this gives us multiple records for student and subject combination however the scores are in the correct columns. Then all we have to do now is condense the result set using the AVG aggregate function like so:
select
student,
subject,
 avg(if(yr=2016,score,null)) `2016`,
avg(if(yr=2016,score,null)) `2016`,
avg(if(yr=2017,score,null)) `2017`
from
test
group by
student,
subject
order by
student,
subject
Well that was easy. Now your boss walks in and tells you data for 2015 is missing and he wants you to now give him a pivot by subject... your reaction 😭😭😭
We obviously need a smarter way to do this... wait a minute, we have prepared statements and JSON functions in MySQL, we can build a procedure to do just that. Lets see
Then we build the looping IFs (@lps) by looping through the @cl and using data[0] to pick the summary function and insert the if statement inside it. Finally we use the current value of the object in @cl to compare whether the value in cols[0]=@cl[@i] in each iteration. If this is true then we provide the json key for data[0] else we provide null. By the end of this harder to digest than concrete logical loop we get @lps=' avg(if(yr=2016,score,null)) `2016`, avg(if(yr=2017,score,null)) `2017`'
The last part is just to build a prepared statement from @rwc, @lps and qry. Run that statement and voila!!! music to our ears.
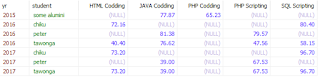
For reasons well known to my insane neurons, I decided to call my procedure pr_json_pivot, and I put it to the test by running call pr_json_pivot('select * from test', '["student", "subject"]', '["yr"]', '[{"score":"AVG"}]') and what do you know... seems to be working:

so now if my boss said I am missing data for 2015, all I do is add those records to the table test and rerun the procedure

But wait, he said he wants to see per year the student's total scores tabulated by subjects... not an issue I just change the right 3 parameters (call pr_json_pivot('select * from test', '["yr", "student"]', '["subject"]', '[{"score":"SUM"}]') ) and am done, muahaahahahaha *evil lough of success* 😁😁😁
Hmmmm 😕wait a minute Tawonga, if you are only using elements 0 for the cols and data parameters why make them arrays in the first place?... Well the answer is that complex pivots might require more than one data fields, for example if I was tracking exam centers I might want each subject column to be split by exam center, i would then need to tabulate by both subject and exam center. Also if I want to do some statistical analysis I might want to have the SUM, AVG, and COUNT in the same table, I would then need multiple data elements for this to work. This code version only does single factor data pivoting using cols[0] and data[0] parameters. I plan to fully support this in future versions of the code, however we can still do some simple distribution analysis with call pr_json_pivot('select * from test', '["score"]', '["yr"]', '[{"student":"count"}]')
 Enjoy
Enjoy

The solution is to create computed columns in our select statement such that for any record that is for 2016 falls in the 2016 column and records for 2017 fall in 2017. Something like this:
select student, subject, if(yr=2016,score,null) `2016`, if(yr=2017,score,null) `2017` from test
Ok, at this point you are already beginning to see the problem here, 1- you need to know all values of yr in advance as these are hard coded into your select query and 2- to just change the column on which you pivot requires a change in your code... Anyways lets continue. Now you will notice that this gives us multiple records for student and subject combination however the scores are in the correct columns. Then all we have to do now is condense the result set using the AVG aggregate function like so:
select
student,
subject,
 avg(if(yr=2016,score,null)) `2016`,
avg(if(yr=2016,score,null)) `2016`, avg(if(yr=2017,score,null)) `2017`
from
test
group by
student,
subject
order by
student,
subject
Well that was easy. Now your boss walks in and tells you data for 2015 is missing and he wants you to now give him a pivot by subject... your reaction 😭😭😭
We obviously need a smarter way to do this... wait a minute, we have prepared statements and JSON functions in MySQL, we can build a procedure to do just that. Lets see
- The first part of your select is just the columns from your table that you want to have as row headings, this same combination is what we are using for the group by and sort by
- The second part is what I call the looping IFs. These will match the number of distinct values of the records in your table and these will be your column headings. This part also has your aggregate function and the summary field
- The last part is your data source which can be a table, a view or even another complex select
So lets build a procedure xtab(qry,rws,cols,data) that can be called like xtab('select * from text','["student","subject"]','["yr"]','[{"score":"AVG"}]').
- the first qry parameter is just the select query that gives me the raw data my procedure will work on
- the rws is a json array of which fields from my qry I want to use as my row headers
- the cols is a json array of the fields I want to use as my column headers, we will stick to a json array of length 1 for now... you know for complexity management reasons
- and lastly the data is a json array of the json objects of the form {field:function}. The field specifies what data element I want to summarize and the function is the MySQL aggregate function for condensing the data
Now the procedure code will now look like
CREATE DEFINER=`root`@`localhost` PROCEDURE `xtab`(
IN `qry` LONGTEXT,
IN `rws` JSON,
IN `cols` JSON,
IN `dat` JSON
)
LANGUAGE SQL
NOT DETERMINISTIC
CONTAINS SQL
SQL SECURITY DEFINER
COMMENT 'Creates a crosstab from any SQL'
BEGIN
# Prepare the columns
set @cl=concat('set @cl= (select
concat(\'[\', group_concat(distinct json_quote(concat(q.', replace(json_extract(cols,'$[0]'),'"','`'),')) order by q.', replace(json_extract(cols,'$[0]'),'"','`'),' asc separator \',\'),\']\')
from
(', qry,') q)');
PREPARE stmt1 FROM @cl;
EXECUTE stmt1;
DEALLOCATE PREPARE stmt1;
# now @cl has a list of all our column values
# create the row selection sql by traversion the @cl object
set @rwc = '';
set @i=0;
REPEAT
set @rwc = concat(@rwc,'q.',replace(json_extract(rws,concat('$[',@i,']')),'"','`'), if(@i + 1 < json_length(rws),', ',''));
set @i = @i + 1;
UNTIL @i >= json_length(rws) END REPEAT;
#create the column looping ifs section using the function in the data json
set @i=0;
set @lps='';
REPEAT
set @dc = replace(replace(json_keys(dat,'$[0]'),']',''),'[',''); #-- Get the data colunm
set @fn = json_unquote(json_extract(dat,concat('$[0].',@dc)));
set @lps = concat(@lps,@fn,'(if(q.',replace(json_extract(cols,'$[0]'),'"','`'),'=\'',json_unquote(json_extract(@cl,concat('$[',@i,']'))),'\',q.', replace(@dc,'"','`') ,',null)) `',json_unquote(json_extract(@cl,concat('$[',@i,']'))),'`',if(@i+1 < json_length(@cl),', ',' '));
set @i = @i + 1;
UNTIL @i >= json_length(@cl) END REPEAT;
#build the final xtab sql
set @stmt=concat('SELECT ',@rwc,', ',@lps,'FROM (',qry,') q GROUP BY ',@rwc,' ORDER BY ', replace(@rwc,',',' ASC, '));
#run the crosstab SQL
PREPARE stmt1 FROM @stmt;
EXECUTE stmt1;
DEALLOCATE PREPARE stmt1;
END
We begin by preparing the data that is going to be our column headers by running the query select distinct cols[0] from qry then group concatenating the result set to create a json array. When the prepared statement runs. At this point @cl='["2016","2017"]'
Then we prepare @rwc to be the row headers part. after this loop comletes @rwc='student,subject'
The last part is just to build a prepared statement from @rwc, @lps and qry. Run that statement and voila!!! music to our ears.
For reasons well known to my insane neurons, I decided to call my procedure pr_json_pivot, and I put it to the test by running call pr_json_pivot('select * from test', '["student", "subject"]', '["yr"]', '[{"score":"AVG"}]') and what do you know... seems to be working:

so now if my boss said I am missing data for 2015, all I do is add those records to the table test and rerun the procedure

But wait, he said he wants to see per year the student's total scores tabulated by subjects... not an issue I just change the right 3 parameters (call pr_json_pivot('select * from test', '["yr", "student"]', '["subject"]', '[{"score":"SUM"}]') ) and am done, muahaahahahaha *evil lough of success* 😁😁😁

Hmmmm 😕wait a minute Tawonga, if you are only using elements 0 for the cols and data parameters why make them arrays in the first place?... Well the answer is that complex pivots might require more than one data fields, for example if I was tracking exam centers I might want each subject column to be split by exam center, i would then need to tabulate by both subject and exam center. Also if I want to do some statistical analysis I might want to have the SUM, AVG, and COUNT in the same table, I would then need multiple data elements for this to work. This code version only does single factor data pivoting using cols[0] and data[0] parameters. I plan to fully support this in future versions of the code, however we can still do some simple distribution analysis with call pr_json_pivot('select * from test', '["score"]', '["yr"]', '[{"student":"count"}]')


Comments
Post a Comment